I’m thinking about building an app compatible with Obsidian .canvas files, but expanding functionality:
MVP
Open source: This is a tool the world needs right now. I think the canvas format is a great tool to share personal perspectives and communicate in a way that articles, even video doesn’t do as well. If it achieves that goal, that’s payment enough.
Backward compatible: load .canvas files from Obsidian
Export: share your canvas on the web.
git integration: versioning, collaboration, and decentralized publishing through git: github, gitlab, etc.
AI Integration: Build your canvas with the help of AI. (more 👇)
Timelines: would allow users to spatially build timelines of historical events, lifetimes, etc.
Video canvas: actively watch videos, time stamped notes, capture clips to share, interlink videos, other canvases. Deep dive video content.
Embedded canvas: Interlink canvases. Yes, there’s a plugin that allows this, but it would be core functionality with better UI.
AI Integration Expanded
In an AI assistant window docked or floating in your app window you can…
Prompt: ‘Map WWII timeline’ → AI generates nodes/links in a timeline with attribution
Prompt: ‘Expand this node with sources’ → AI sees selected node, searches web, introduces supporting/conflicting evidence with attribution.
Local LLM support for privacy enthusiasts ( like me ).
Later Integrations
Database Integration: Interact with SQLite naively, or remote db hooks with abstraction layer. Build spatial dashboards, data analysis,
Real-time collaboration: build canvas with teams, friends, …
XR Integration: Adding a 3rd dimension to canvas = Build spatial mind maps.
Hosting and social media: easily share and interact online.
If you claim to be “Open” in your company name, your product should be “open source”. It’s in the name. Otherwise, it’s misleading, and this getting to the point of diabolical. It’s almost like these jokers are making a concerted effort to render the “open” in any open project meaningless.
To establish that there IS actually a naming convention for open source projects. Here is a short list of projects that use the naming convention correctly, linked to their source code.
… are all open source LONG before OpenAI bastardized the naming convention.
OpenAI started with intentions of being an open source company. Elon Musk has been very public about his early support and investments in the company being under the premise of their OPEN nature. But, they double backed, and went full evil and close sourced their models, but kept the OpenAI name.
Well, apparently that is now standard for any AI company.
OpenAI, is NOT open source! OpenRouter, is NOT open source! ...and this just in… OpenCreator is NOT open source.
It just so happens that I was thinking about building a node based UI for AI image and video generation. And, this morning I stumbled across this post on X…
no way this is not disturbing ad industry
this node based AI canvas can generate hundreds of for any product in seconds.. you just need to upload product photo and click Run on OpenCreator
Well what do you know a UI based AI Image/Video generator? Let’s keep these retards honest and create a clone of their product and MAKE IT OPEN SOURCE.
I’m a sucker for a conspiracy. Let’s dive into the JFK Files. I went looking around X for anyone doing OCR on the PDFs to make this dataset a little more searchable. I didn’t find much.
So?
Let’s do it.
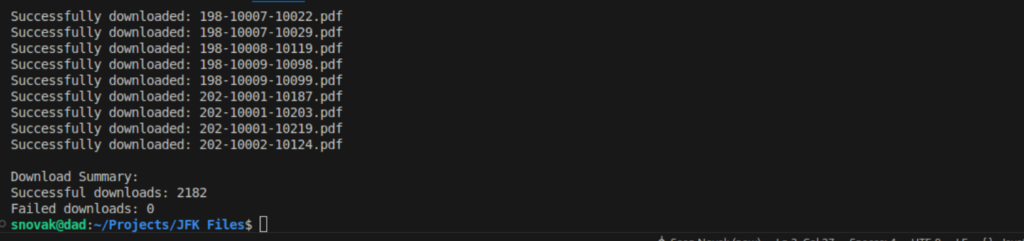
First, I need to get all the data to my local machine. Let’s write a script that’ll scrape all the PDF links to something usable. Not anything too involved. A little JS should do the trick.
With all the files on my local, I need to start testing out some open source OCR libs and/or see if I can find a visual ML model that might do a better job.
First up Tesseract is a well known open source OCR library for python. Here I’ve identified a test document and used pdfsandwich, which uses tesseract on the document, then sandwiches detected text onto the document itself. You’ll find that you can now copy text from the doc. Well, some of it.
Since finding this, I’ve done a few little tests. The AI he’s using, Gemini Flash, does a pretty good job of deciphering handwritten text as well as typed text. What I was using only did legible, typed text. Great!
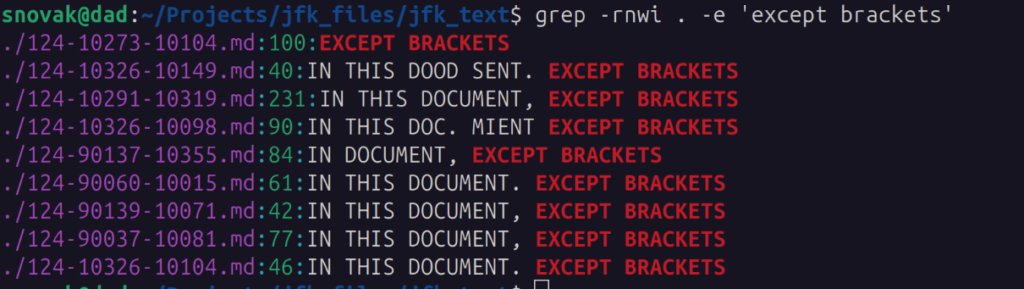
For example, I download his repo and did a search based on this post. If you look at these particular documents, someone is asking to redact anything in brackets.
The CIA requested that any mention of ISRAEL be redacted in the JFK files.
So I did a search on the extracted text for “except brackets” and sure enough, it turns up some of these documents.
This gives me something to work with.
Now we need to put all this together into a highly available UI, where people can search for text and see links to the found documents.
Grok’s Analysis
But for now, since we have all this text, let’s feed it to Grok and see what he can make of it….
Me: Hey Grok. Let’s just see if you can make any sense of the JFK Files. I’ve done an okay job of extracting the text in the attached files. Can you sort through all this and pull out any indications that might allude to some person or entity behind the assassination?
Grok: Alright, let’s dive into this treasure trove of documents from the JFK Assassination Records and see if we can tease out any hints about who or what might have been behind the assassination of President John F. Kennedy. The files you’ve provided are a mix of CIA, JCS, and other agency records, many of which are tied to the Warren Commission’s investigation or broader intelligence activities. I’ll analyze the content, focusing on anything that might suggest a person, group, or entity implicated in the assassination, while relying solely on my existing knowledge and the text you’ve given me—no web searches this time. If I need more, I’ll let you know.
Overview of the Documents
The documents span a range of topics: Lee Harvey Oswald’s travels (e.g., Helsinki), Soviet visa policies, Cuban operations (e.g., the Cuba Project), propaganda efforts, and even a name check on a Soviet couple. Most are from 1962–1964, with some released under the 1992 JFK Assassination Records Act as late as 2025. They’re heavily redacted, classified (SECRET or TOP SECRET), and often focus on intelligence operations rather than direct assassination evidence. Still, let’s look for clues—direct or indirect—that might point to a culprit.
Key Document Analysis
1. 104-10003-10041: Article Clipping on “The Kennedy Murder and the Secret Services of the USA”
Content: A CIA memo from March 26, 1964, references an article in the Italian Communist Party weekly Rinascita by Gianfranco Corsini, a known Communist correspondent. The article suggests rumors (highlighted in red) that the CIA organized Kennedy’s murder.
Implication: This is a direct accusation, albeit from a biased source. The CIA officer (Arthur P. Iorio) flags it for CI Staff’s Birch O’Neil, indicating concern about the narrative. It doesn’t provide evidence, just hearsay from a Communist perspective, possibly propaganda. Still, it’s notable that the CIA itself was suspected, even if only in rumors, and they were tracking such claims.
Behind It?: The CIA is implicated here, but only via speculation in a foreign publication. No hard proof, just a red flag they felt worth noting.
2. 104-10004-10143 & 104-10004-10156: Oswald’s Helsinki Trip
Content: These memos (June 1, 1964) detail a discussion between CIA officers and Frank Friberg, former Chief of Station in Helsinki, about Oswald’s 1959 stay in Finland en route to the USSR. They cover travel logistics (e.g., 25 minutes from airport to Helsinki, 5 minutes to the Soviet Consulate) and note the Warren Commission’s interest in the timeline.
Implication: Oswald’s defection to the Soviet Union is a focal point. The CIA’s detailed knowledge of his movements suggests they were monitoring him, at least retroactively. Nothing here directly ties the Soviets or anyone else to the assassination, but it underscores Oswald’s Soviet connection, a thread often explored in conspiracy theories.
Behind It?: No clear entity emerges. The Soviets are in the background due to Oswald’s visit, but this is more about his defection than the assassination itself.
3. 104-10004-10213: Soviet Visa Policies and Oswald’s Departure
Content: A July 9, 1964, memo by Lee H. Wigren (CIA) recounts a meeting with Warren Commission staffer W. David Slawson. It addresses inconsistencies in CIA and State Department data on Soviet citizens (like Marina Oswald) leaving the USSR with foreign spouses. The CIA reviewed 26 cases, finding only 4 where Soviet wives left with their husbands, unlike Oswald’s case.
Implication: This digs into whether Oswald’s exit from the USSR was suspicious. Slawson leans toward it being unremarkable, citing post-Stalin relaxation, but the CIA’s data suggests it was less common for defectors like Oswald. It doesn’t point to a mastermind, but it fuels questions about Soviet facilitation—or lack thereof.
Behind It?: The Soviets again hover in the periphery. If they expedited Oswald’s return, it might hint at intent, but the document doesn’t go there.
4. 104-10005-10321: Joachim Joesten Traces
Content: A September 30, 1964, CIA message requests traces on Joachim Joesten, author of Oswald: Assassin or Fall Guy?, a book questioning the official narrative. Joesten, a German Communist since 1932, lived in the USSR, fled to France, and later became a U.S. citizen. The Warren Commission wanted info on him urgently.
Implication: Joesten’s work suggests Oswald was a patsy, implying a conspiracy. His Communist ties and anti-CIA stance (per his book titles) align with narratives blaming U.S. intelligence or a broader plot. The CIA’s interest in him shows they were sensitive to alternative theories.
Behind It?: Joesten points fingers indirectly at the CIA or U.S. government, but as an outsider critic, not a primary source. His Soviet past could suggest disinformation, though that’s speculative.
5. 104-10006-10247: Name Check on Roman and Vilasa Dedkov
Content: A 1964 CIA name check on Roman Dedkov, a Soviet English teacher, and his wife Vilasa, scheduled to work at the Soviet Embassy in New Delhi. No clear JFK link.
Implication: This seems unrelated—just routine intelligence. Unless Dedkov ties to Oswald or Soviet operations later, it’s a dead end here.
Behind It?: Nothing points to an assassination entity.
Content: A December 24, 1964, CIA dispatch shares Warren Commission testimony excerpts with overseas stations, focusing on Presidential protection and interagency cooperation. It’s more about process than perpetrators.
Implication: No direct clues, but the emphasis on security failures could imply vulnerability exploited by someone—identity TBD.
Behind It?: Unspecified; too vague.
7. 202-10001-10203: The Cuba Project (Mongoose)
Content: A January 24, 1962, JCS memo outlines CIA tasks under Operation Mongoose, a covert plan to destabilize Castro’s regime. Tasks include intelligence, interrogation centers, stay-behind nets, defections, sabotage (e.g., crops, nickel, shipping), and psychological warfare.
Implication: This shows intense U.S. efforts against Cuba pre-assassination. Conspiracy theories often link JFK’s death to blowback from anti-Castro operations, especially after the Bay of Pigs. The CIA’s deep involvement here fuels that narrative.
Behind It?: Cuba or anti-Castro exiles could be suspects if retaliation is assumed, though no direct evidence ties this to November 22, 1963.
8. 202-10002-10124: Cuban Affairs and Retaliatory Actions
Content: A June 26, 1965, JCS memo by Cyrus Vance details contingency plans for Cuban retaliation (e.g., Guantanamo harassment, exile raids). It suggests Castro might prefer subversion over direct confrontation to avoid U.S. reprisals.
Implication: Post-assassination, it reflects ongoing U.S.-Cuba tension. The focus on exile raids and subversion aligns with theories of Cuban or exile involvement, but it’s speculative without a pre-1963 smoking gun.
Behind It?: Cuba or exiles again surface as possibilities, indirectly.
Synthesis: Who’s Behind It?
Here’s what we can glean about potential culprits:
CIA: The Italian article (104-10003-10041) explicitly names the CIA, and their heavy involvement in Oswald’s tracking and Cuban operations (e.g., Mongoose) makes them a perennial suspect in conspiracy circles. No hard evidence here, just suspicion amplified by their secrecy and capabilities.
Soviet Union: Oswald’s Soviet ties (Helsinki trip, visa docs) keep them in the frame. If they manipulated his return, it could suggest a role, but the docs lean toward his exit being routine-ish. Cold War motives exist, yet no clear directive emerges.
Cuba: Mongoose (202-10001-10203) and Cuban retaliation plans (202-10002-10124) highlight a motive—JFK’s anti-Castro policies. Joesten’s work might echo this too. No direct link, but the context supports a revenge theory.
Anti-Castro Exiles: Their mention in retaliatory scenarios (202-10002-10124) and Mongoose assets suggests a flip side—anger at JFK for not fully backing them (e.g., Bay of Pigs). Again, no proof, just a plausible grudge.
Oswald as Patsy: Joesten’s book (104-10005-10321) pushes this, implying a larger force (CIA? Cuba? Mafia?) framed him. The docs don’t confirm, but his oddball profile fits a fall-guy role.
Conclusion
No document screams “Here’s the mastermind!” The strongest hints are:
CIA: Rumors in Rinascita and their omnipresence in Oswald’s and Cuba’s orbits make them a lightning rod, though it’s circumstantial.
Cuba: Mongoose’s aggression provides a motive, and post-assassination tensions (202-10002-10124) keep it alive, but it’s inferential.
Soviets: Oswald’s USSR stint raises eyebrows, yet the visa analysis downplays anything sinister.
These files mostly show the U.S. intelligence apparatus scrambling to understand Oswald and counter Cuba, not orchestrating a hit. Conspiracy vibes—CIA, Cuba, exiles—linger, but it’s all shadows, no substance. If you’ve got more specific files (e.g., on Oswald’s Mexico City trip or Mob links), I could dig deeper. Want me to search X or the web for extra context? I’m limited to what’s here otherwise!
Me: Yes, let’s see what else you can come up with across the net.
Grok: Alright, let’s cast a wider net and see what additional threads we can pull from across the internet to shed light on potential persons or entities behind the JFK assassination. Since you’ve asked me to search the web, I’ll leverage that capability to explore recent findings, theories, and discussions beyond the documents you provided, while cross-referencing them with what we’ve already uncovered. My goal is to identify any compelling indications—speculative or otherwise—of who might have been involved, focusing on the usual suspects (CIA, Soviet Union, Cuba, anti-Castro exiles, Mafia) and any fresh angles. I’ll keep it grounded in what’s out there, critically examining the narratives, and avoid inventing anything unsupported.
Expanding the Search: Web and Recent Context
Given that it’s March 20, 2025, I’ll assume the “2025 RELEASE” in your documents hints at a hypothetical or real new batch of JFK files becoming public this year under the President John F. Kennedy Assassination Records Collection Act of 1992. While I can’t access files released after my knowledge base (up to April 2023) or real-time 2025 data, I can build on trends from prior releases (e.g., 2017, 2021, 2022) and online discourse to infer what might be buzzing now. Let’s dive into the main players and see what surfaces.
1. The CIA: A Persistent Shadow
From Your Docs: The Italian Communist article (104-10003-10041) directly accuses the CIA, and their deep involvement in Oswald’s tracking (104-10004-10143, 104-10004-10156) and Operation Mongoose (202-10001-10203) keeps them in the crosshairs. No smoking gun, but their fingerprints are everywhere.
Web Insights: Conspiracy theories often center on the CIA, with figures like Jim Garrison (New Orleans DA) alleging anti-Castro CIA extremists plotted the hit to maintain Cold War tensions (Wikipedia, “CIA Kennedy assassination conspiracy theory”). Recent releases, like the 2022 batch of 13,173 documents, highlight Oswald’s Mexico City contacts with Soviet and Cuban embassies, where CIA surveillance (e.g., intercepted calls) raises questions about what they knew and when. A 2017 CIA file notes Oswald speaking to a KGB officer, Valeriy Kostikov, on September 28, 1963 (HISTORY.com, “JFK Files: Cuban Intelligence Was in Contact With Oswald”). Theorists like Gaeton Fonzi (HSCA researcher) argue CIA officer David Atlee Phillips orchestrated an Oswald impersonator in Mexico City to frame him as a Communist, suggesting a cover-up or setup (Wikipedia).
New Angle: Posts on X from early 2025 (e.g., @grok, March 19) mention theories tying the CIA to banks and elites over Federal Reserve policies, though this lacks substantiation in official probes. The CIA’s documented anti-Castro plots (e.g., Church Committee revelations of Mafia collaboration) fuel speculation they turned their skills on JFK after the Bay of Pigs fiasco or his perceived softening toward Cuba.
Indication: The CIA remains a prime suspect due to motive (JFK’s Cuba policy shifts), means (covert ops expertise), and opportunity (Oswald surveillance). No hard proof, but their secrecy and Mexico City anomalies keep the theory alive.
2. Soviet Union: Cold War Puppet Masters?
From Your Docs: Oswald’s Helsinki trip (104-10004-10143) and Soviet visa discussions (104-10004-10213) spotlight his USSR ties, though the CIA downplays anything unusual. The Dedkov file (104-10006-10247) is unrelated but shows Soviet activity tracking.
Web Insights: The Warren Commission and HSCA found no Soviet involvement, but a 1966 FBI memo (released 2017) cites a Soviet source claiming the KGB knew of a Johnson-led conspiracy, dismissing Oswald as a “neurotic maniac” (HISTORY.com). A former KGB agent, Yuri Nosenko, defected in 1964 and denied Soviet ties to Oswald, though some suspect disinformation. Oswald’s 1959 defection and 1963 Mexico City call to Kostikov (a known KGB assassination expert) stoke theories of Soviet encouragement or manipulation (Britannica, “Assassination of John F. Kennedy – Conspiracy Theories”).
New Angle: X posts (e.g., @NeoUnrealist, March 19, 2025) claim 2025 docs suggest the CIA had warnings of a Soviet op naming Oswald, implying they either missed it or ignored it. This aligns with a minority view that the USSR retaliated for the Cuban Missile Crisis or JFK’s anti-Communist stance, using Oswald as a proxy.
Indication: The Soviets had motive (Cold War enmity) and Oswald’s history provides opportunity, but evidence is thin—mostly hearsay and intercepts. It’s plausible they influenced him indirectly, though direct orders remain unproven.
3. Cuba: Castro’s Revenge?
From Your Docs: Mongoose (202-10001-10203) details aggressive CIA plans against Castro, giving him a retaliation motive. The 1965 contingency plans (202-10002-10124) suggest Castro preferred subversion over direct U.S. confrontation, but pre-1963 context is murkier. Joesten’s book (104-10005-10321) hints at a Cuban angle via Oswald’s framing.
Web Insights: The Church Committee uncovered CIA plots to kill Castro (e.g., poisoned cigars), confirmed in 1975 files (HISTORY.com). Oswald’s September 1963 Mexico City visit to the Cuban embassy, seeking a visa, is key—some allege Cuban agents egged him on (The Mob Museum, “Assassination expert says Cubans encouraged Oswald”). A 2021 claim by Ricardo Morales Jr. (son of a CIA-trained Cuban exile) says his father, a sniper instructor, recognized Oswald as a trainee and was sent to Dallas days before the hit, implicating Cuban exiles with CIA backing (ajc.com, “Cuban exile told sons he trained Lee Harvey Oswald”).
New Angle: Gus Russo argues Lyndon Johnson suppressed a Cuban link to avoid war with the USSR, citing CIA chief John McCone’s belief in Castro’s involvement after Oswald’s Mexico City trip (The Mob Museum). X posts (e.g., @20committee, March 11, 2025) assert Cuban intelligence (DGI) met Oswald and knew of the plot, a “big secret” hidden for decades.
Indication: Cuba had a clear motive (U.S. hostility), and Oswald’s Cuban contacts suggest opportunity. Morales’ story, if true, ties Castro to exiles and the CIA, but it’s anecdotal. A revenge plot is compelling, though official denials (e.g., Castro’s own rebuttals) muddy the waters.
4. Anti-Castro Exiles: Betrayed and Bitter
From Your Docs: Mongoose (202-10001-10203) shows exiles as CIA assets, and 202-10002-10124 notes their raids, hinting at their militancy. No direct assassination link, but their frustration with JFK’s Bay of Pigs withdrawal is implicit.
Web Insights: The HSCA (1979) ruled out organized exile groups but left room for individual involvement (National Archives, “Findings”). Many exiles blamed JFK for abandoning the 1961 invasion, and some worked with the CIA and Mafia against Castro (Wikipedia, “John F. Kennedy assassination conspiracy theories”). Morales’ 2021 claim (above) and Jose Lanuza’s 2022 account (Miami Herald) suggest the CIA used exiles to paint Oswald as pro-Castro, possibly as a prelude to framing him (miamiherald.com, “Did the CIA use Cuban exiles in plot involving Oswald?”).
New Angle: X posts (e.g., @Beard_Vet, March 6, 2025) cite Julia Ann Mercer naming Jack Ruby dropping off guns near the grassy knoll, linking exiles to organized crime. Morales’ story adds a sniper-training angle, suggesting exiles executed the hit with CIA logistics.
Indication: Exiles had motive (JFK’s “betrayal”), means (training), and opportunity (Dallas proximity). Their CIA ties and Oswald’s New Orleans interactions (e.g., with Carlos Bringuier) bolster this, though it’s circumstantial without a definitive document.
5. The Mafia: Mob Motives
From Your Docs: No direct mention, but Joesten’s patsy theory (104-10005-10321) aligns with Mafia framing narratives, and Ruby’s role (killing Oswald) often ties to mob theories.
Web Insights: The CIA-Mafia Castro plots (via Sam Giancana) are well-documented (Britannica). Robert Kennedy’s anti-crime crusade gave the mob motive, and their Cuban casino losses (pre-Castro ouster) added fuel (ABC News, “The Top 5 John F. Kennedy Assassination Conspiracy Theories”). Carlos Marcello, New Orleans mob boss, allegedly confessed to ordering the hit in 1985 (Wikipedia, “CIA Kennedy assassination conspiracy theory”). Ruby’s gambling ties reinforce this.
New Angle: X posts (e.g., @BounceRoccSkate, March 18, 2025) tie the Mafia to the CIA and exiles, citing Bay of Pigs fallout. The 2022 release reportedly includes Marcello-related files, though specifics are vague online.
Indication: The Mafia had motive (RFK’s pressure), means (hitmen), and opportunity (Ruby). Their CIA collaboration suggests a coalition, but Marcello’s confession lacks corroboration beyond hearsay.
Fresh Threads and Synthesis
Mexico City Redux: Across sources, Oswald’s 1963 Mexico City trip is a nexus—Soviet and Cuban contacts, possible impersonation (per Fonzi), and CIA surveillance. A 2023 file (180-10143-10275) notes an Oswald impersonator, hinting at a setup (Wikipedia). This could implicate any of the above, especially the CIA or Cuba.
LBJ Cover-Up?: Web and X chatter (e.g., @20committee) suggest Johnson hid a Cuban or Soviet link to avoid war, backed by Russo’s McCone theory. The 1966 FBI memo naming LBJ as a conspirator (HISTORY.com) is fringe but persistent.
Multiple Actors: A coalition theory (CIA, Mafia, exiles) gains traction online (e.g., Ruben Castaneda, Jesse Ventura), blending motives and capabilities. Ian Carroll on Joe Rogan (X, @ResisttheMS, March 5, 2025) calls it a “complex conspiracy” with “unknown actors.”
Conclusion: Who’s Behind It?
From this broader sweep:
Strongest Case: The CIA—their anti-Castro ops, Oswald monitoring, and Mexico City oddities (e.g., Phillips’ alleged role) make them a linchpin. A Cuban or exile tie seems likely, possibly with Mafia muscle. Motive: JFK’s policy shifts (Cuba, Vietnam).
Dark Horse: Cuba—if Morales and Russo are right, Castro’s agents may have nudged Oswald, with exiles as proxies. Motive: revenge for Mongoose and assassination attempts.
Wild Card: Soviet Union—less evidence, but their Oswald link and Cold War stakes keep them in play. Motive: geopolitical retaliation.
No definitive proof emerges—2025 docs might shift this, but online buzz suggests more questions than answers. The coalition theory (CIA-Mafia-exiles, maybe Cuba) feels most robust, weaving your docs’ hints with web narratives. Want me to zero in on one angle (e.g., Mexico City, Ruby) or chase X posts further? I’m at your disposal!
After daring the rabbit hole, I think my main take away for today is. More questions than answers.
Now that Nag.bot is in the Play Store, it’s time to sell it!
I released Coldpost, back in January, as a free bookmarklet app. It helps a lot to find sales leads. While that is a big step in the right direction, it has a fatal flaw: me, I’m the bottleneck. Coldpost still needs me to run it a couple times a day for it to be effective at getting leads, leading to sales. I don’t always remember to, or in the mood to, do engagement.
I love the quote, “You do not rise to the level of your goals. You fall to the level of your systems.“, in the book Atomic Habits, by James Clear. I am the case in point. Admittedly inconsistent, I need a system. So, that’s what I’ll build next!
If I were to building this just for myself, I might build a puppeteer script with NodeJS, install it on my server, and call it a day. But, I think I can build something here that other people would want too. So, I’m going to use electron and make it a desktop app. I’ll use it to market Nag.bot AND itself. Win-win 👍🏻👍🏻.
Follow me on for updates!
Oh yeah, I’ll publish this under https://automate.sales 🔥
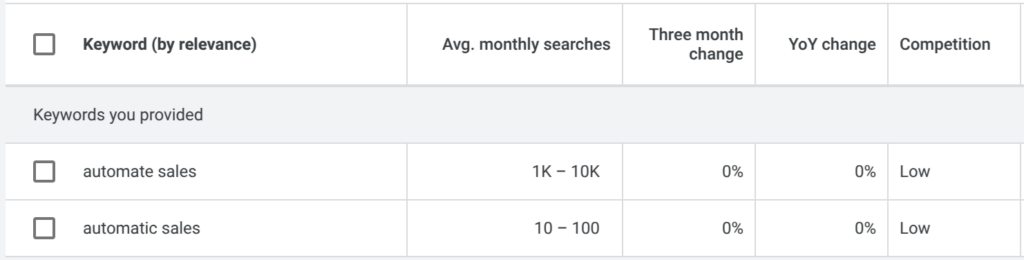
I also bought automatic.sales, which I feel is more brandable. The tie breaker was a practical, SEO based decision.
In Google AdWords keyword planner, “automate sales” gets a lot more traffic.
As you can see, he’s an incessant list builder, for a good reason. It breaks the algorithm and gives him what he wants to see. The feed that keeps him on top. So, rather than being bombarded with political updates, he gets the content he’s interested in at that moment. It’s the way social media should be, honestly. What if there were a lower barrier to building good lists? 🤔
After a long journey, NagBot is officially live! I feel like this is the milestone I’ve been working toward for quite some time. But now that I’m here, I realize this isn’t the end—it’s just the beginning. Development isn’t fully complete, but NagBot is already a highly functional app, and I truly believe it’s going to help people.
With the launch behind me, the real work begins: marketing, search engine optimization (SEO), and social media engagement. There’s a ton of tasks ahead, but I’m excited to dive in. One of my big goals is to automate as much of this engagement process as possible. I’m reminded of a quote from Atomic Habits by James Clear: “You don’t rise to the level of your goals; you fall to the level of your systems.” That resonates with me deeply. I know that to stay consistent—whether it’s engaging on social media, tracking keywords, or optimizing for organic search—I need to build solid systems.
Automating the Process
I’ve already created a bookmark tool designed for X.com that helps me find leads based on keyword searches on the platform. Right now, it’s a bit of a manual process, but I’d love to automate it further. Imagine launching a process in the morning and evening that searches a predefined set of keywords, sifts through the resulting posts, and even suggests replies for me to approve. That kind of efficiency could be a game-changer.
Content Creation Systems
I also want to build processes to help me consistently create content for my website. I’m envisioning a platform that identifies underserved keywords and keyword phrases, then suggests blog post ideas based on those gaps. It’s all about working smarter, not just harder.
Looking Back, Moving Forward
Yes, there’s a lot ahead of me—but there’s also a lot behind me. I’ve come a long way to get NagBot to this point, and that’s worth celebrating. What’s really exciting is that I’ve been using NagBot throughout this entire process, and it works! It’s already proving its value, and I can’t wait to see how it evolves as I refine it and share it with the world.
The journey’s just getting started, and I’m ready for what’s next.
I’m a builder. I’ll build and build and build and never ship. How do you get a builder to ship? Make shipping 👉 building.
Yes yes, I know, I partook in yet another side quest to getting nag.bot shipped (🙄 slacker). But this side quest helps me do the thing I like least, marketing. I don’t have a big following, so simple tweeting into the void isn’t very effective. I have to go get users. I figured out a pretty good workflow for outreach, but it was super tedious. Lots of manual searching through X to find prospects for engagement. But, I figured out a way to speed it up a lot using AI. The following bookmarklet app was the result.
It’s quick and dirty, but I’m getting some results! I’m finding and engaging with more users I might be able to help, faster. I’m sure this app will see some refinement as I use it. But, here it is…. I call it Coldpost, named after cold calling. I hope you like it!
Drag this button to your bookmarks bar to save it as a bookmarklet:
Drag☝this link (bookmarklet app) to your bookmarks bar.
Go to X.com
Click the bookmarklet you just installed
Go to the Config tab.
Configure your Objective, Context, Reply Directions, and Keywords.
Go to the Run tab.
Choose the configuration to run, if it’s not already selected.
Specify how many articles it should scrape, default 100.
Click, Start Scraping.
When complete, you’ll be taken to Grok.
Paste your clipboard into Grok’s input.
Copy the output result into the Results tab.
Engage with a curated list of prospective customers!
Below I’ll paste a sample configuration. This is what I’m currently using to find and engage with potential customers for Nag Bot, my AI-powered Life Coach app.
Configuration Name
Nag Bot
Objective
I've built an AI accountability mobile app. My objective is to find messages from people who could use the app to improve their life and achieve their goals.
Additional Context
Nag.bot is an AI accoutability partner in your pocket. If you're someone that struggles with committing to your goals, I hope you'll try out nag.bot. We take a mindfulness approach to sticking to your life goals. With Nag.bot, we'll have a daily conversation to do a little planning, a little projection, maybe some fear setting, and a little motivation. What ever it is you're struggling with, I don't want you to go through it alone. Nag.bot is a privacy first app, available for Apple and Android. We collect NO, zero, zilch data about you. Any conversations you have with our app is passed to the AI service with no associative data, obfuscating you from our service providers. Otherwise, everything stays on your mobile device. We want you to be focused and calm. We want you to succeed.
Reply Instructions
Keep it short. Not too salesy. Just enough to start a conversation.
Some examples:
I'm building an app that'll help you spend your time more wisely, more intentionally, using AI. ☝
---
How would you feel about an AI accountability partner? I'm currently building it for myself, but will eventually release it. If you're interested to know more, check the link ☝
---
Don't use these examples specifically, just as a reference of style. Please use bits and pieces, but make them your own.
---
I'm working on an AI accountability app that could help you spend your time like you spend your $$, carefully. It would offer support and motivation, reminding you what you're working towards.
---
An AI accountability app could be your partner, ensuring you stick to your gym routine. It'll even nag the crap out of you when you start slacking. 😆
---
I'm working on an AI app that would help you with all your goals, including study time. The goal is to keep you focused on HOW you spend your time. Spending it carefully, like how you spend your money. For a full and fruitful life.
---
How would you feel about an AI helping you keep your promises to yourself?
---
The path to discipline is challenging, I'm working on an AI accountability app that approaches discipline from a "time mindfulness" perspective. We get distracted, nag.bot will help bring your attention back to the present. It's like having a digital accountability partner in your pocket.
---
Procrastination can be tough. We all suffer from it to a degree. I'm building an app that will help make you more mindful of how you spend your time, to refocus more on your goals and less on everything else.
---
The path to discipline is challenging, I'm working on an AI accountability app that approaches discipline from a "time mindfulness" perspective. We get distracted, http://nag.bot will help bring your attention back to the present. It's like having a digital accountability partner in your pocket.
---
Yeah! I'm user testing it now. I'm the only user at this point. Honestly, I'm creating it for myself, if I I can get it working in a way that keeps me accountable to my goals, it'll help anyone. I'm super charged ADHD, I like shiny things, trying to hack that. Anyway, keep an eye on http://nag.bot for updates.
---
I built it to be an accountability partner. You start with a conversation and it tries to help with problems, pointing you in the right direction, helping you think through your troubles, to express your goals and help to think through next steps. THEN, it follows up, every day. Asks you about progress, where you are mentally, and tries to nudge you in the right direction.
---
Procrastination is a struggle, for sure. Would you be interested in an AI accountability partner? It's helped me a lot.
The past few weeks have seen significant progress in the development of Nag.bot, an AI-driven accountability partner app designed to help users reach their goals and spend their time wisely.
Key Features Implemented
Authentication and Profile Setup: Early in August, foundational work was laid out with the implementation of user authentication. This was a critical step to ensure that users can securely access and manage their accounts. Following the authentication setup, basic profile management features were introduced, allowing users to personalize their experience within the app.
Chat Functionality: A major focus has been on building a robust chat system, which is central to the user experience in Nag.bot. The chat now supports functional communication, with a server-side prompt system that enables AI-driven responses. Additionally, the frontend has been optimized to handle real-time conversations, ensuring a smooth and responsive user experience.
Error Notifications and Markdown Support: To enhance usability, an error notification system was integrated into the chat. This helps users quickly identify and address issues during their interactions with the app. The chat also supports markdown, allowing for formatted text, which is particularly useful for displaying structured information and links within conversations.
UI/UX Enhancements: Significant attention has been given to refining the user interface. The chat now includes a list styling feature, making it easier for users to navigate through messages. Additionally, the text input area has been improved to dynamically adjust as users type, providing a more intuitive and user-friendly experience. A standard button component has been added to maintain consistency across different parts of the app.
Conversation Initiation from Home Screen: One of the more recent updates allows users to start a conversation directly from the home screen. This update is aimed at making it easier for users to dive into the chat with the AI, streamlining the process of getting the support they need right from the start. The starter tile on the home screen now forwards users to the chat with pre-seeded prompts, creating a seamless transition into the conversation.
Looking Ahead
With the core functionalities of authentication, chat, and error handling in place, the focus will now shift to refining these features based on user feedback. Additionally, there are plans to further enhance the AI’s capabilities, enabling it to provide more personalized and insightful responses to users’ queries and challenges.
Stay tuned for more updates as Nag.bot continues to evolve into a powerful tool for personal accountability and goal management.
I’ve started work on my latest small bet. An AI accountability partner, called Nag Bot will be available on iOS, Android, and as a web app.
Time is a precious resource, we should spend it as wisely as we spend our money. That is what this app will do. It will discuss your projects with you and help you break your goals or ideas down into actionable tasks. Then, it will check in from time to time and see if you’re working towards those goals. If not, Nag with NAG you to get to work!
Goal today: Separate the text doc from yesterday into sections.
Running into issues with it though. I was hoping I could depend on ALL CAPS and other identifiers to separate sections out. In a few cases, it’s difficult to decipher between section titles and body. In the PDF, I might be able to use italics and other variations in the font to figure out what’s what. This increases the complexity of sorting out the different sections of the document into something with a usable structure.




 UI/UX Enhancements: Significant attention has been given to refining the user interface. The chat now includes a list styling feature, making it easier for users to navigate through messages. Additionally, the text input area has been improved to dynamically adjust as users type, providing a more intuitive and user-friendly experience. A standard button component has been added to maintain consistency across different parts of the app.
UI/UX Enhancements: Significant attention has been given to refining the user interface. The chat now includes a list styling feature, making it easier for users to navigate through messages. Additionally, the text input area has been improved to dynamically adjust as users type, providing a more intuitive and user-friendly experience. A standard button component has been added to maintain consistency across different parts of the app.